


简单介绍
自定义识别词是 MP 的重要功能。它能识别那些与 TMDB 数据库不符的标题。在硬链接过程中,功能会自动修正名称,从而让媒体库顺利完成刮削。
没有特殊标注,下面都会把自定义识别词简称为识别词 。在文章内会有两种识别词,一种是订阅识别词,一种是全局识别词 。其中全局识别词也是可以被订阅使用的
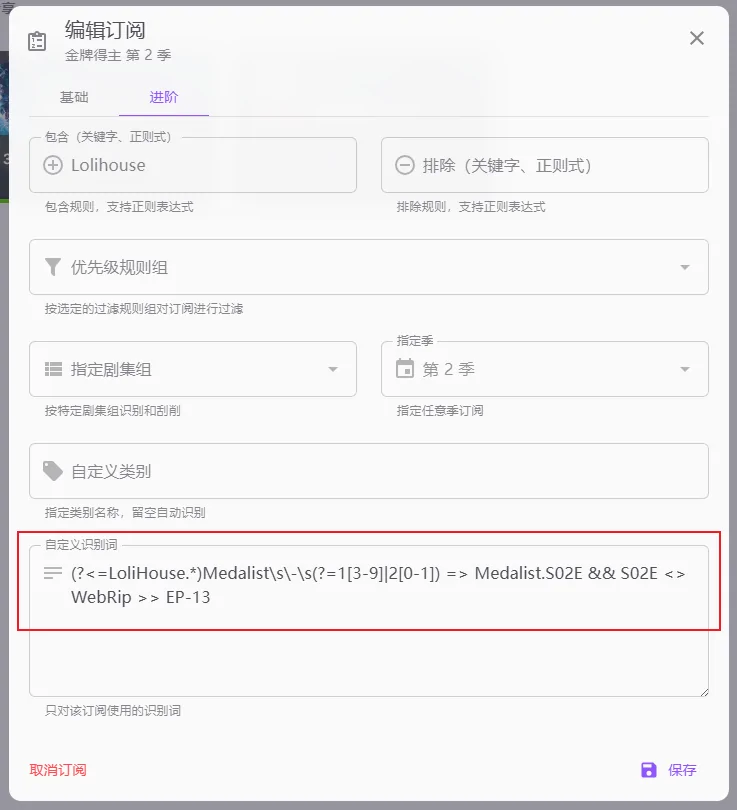
订阅的自定义识别词 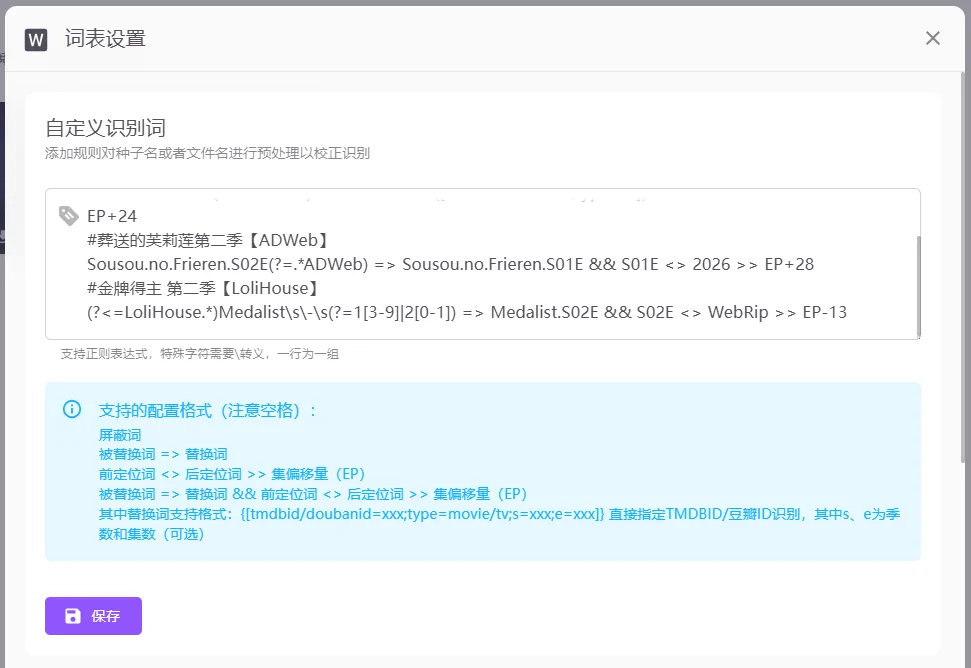
系统使用的自定义识别词
我的理解是现阶段订阅中的识别词只能帮忙检测当前找到的标题是否符合订阅的剧集(发布页面是第14集,但是在TMDB中是第二季第一集,所以需要订阅的这里填写识别词),而媒体整理使用的全局识别词需要在
界面右上角(头像左边再左边)-词表设置里面调整(下载的文件名称还是第14集,创建硬链接需要变成S02E01需要用到全局的识别词)。一般情况下,填写全局识别词就可以了,再重复一遍,订阅也会使用全局识别词。
以下内容如果没有特殊提及,均以动漫花园的这个种子来举例。
种子的发布页面标题为:
[喵萌奶茶屋&LoliHouse] 金牌得主 / Medalist - 14 [WebRip 1080p HEVC-10bit AAC][简繁日内封字幕]种子下载的文件名称为:
[Nekomoe kissaten&LoliHouse] Medalist - 14 [WebRip 1080p HEVC-10bit AAC ASSx2].mkv
新版本(还未发布)会把订阅的识别词和系统的识别词合并,不知道理解得对不对。
https://github.com/jxxghp/MoviePilot/pull/5419
代码先行
看一眼数据框下面的tips:
支持的配置格式(注意空格):
屏蔽词
被替换词 => 替换词
前定位词 <> 后定位词 >> 集偏移量(EP)
被替换词 => 替换词 && 前定位词 <> 后定位词 >> 集偏移量(EP)
其中替换词支持格式:{[tmdbid/doubanid=xxx;type=movie/tv;s=xxx;e=xxx]} 直接指定TMDBID/豆瓣ID识别,其中s、e为季数和集数(可选)
一般用户能用上的就是这一句:被替换词 => 替换词 && 前定位词 <> 后定位词 >> 集偏移量(EP)
然后看了订阅了的NEST大佬的正则:
(?<=LoliHouse.*)Medalist\s\-\s(?=1[3-9]|2[0-1]) => Medalist.S02E && S02E <> WebRip >> EP-13
一头雾水吗?很正常,一拿到手上谁都会懵逼,现在一点点来拆。这个代码分为了四个部分,分别是:
正则部分
(?<=LoliHouse.*)Medalist\s\-\s(?=1[3-9]|2[0-1])替换的文本部分
Medalist.S02E被计算区域
S02E <> WebRip计算方法
EP-13
正则部分
它是标准的零宽断言,它的作用是把标题中的Medalist - 提取出来。这个正则讲人话就是,把这个前面必须有LoliHouse ,后面有一堆杂七杂八的文字,然后后面加一个空格,在加一个-,再加一个空格,然后后面紧跟着有一个数字,数字是13到19或者是20到21 。
(?<=LoliHouse.*): 它要求文本的前面某处必须出现过LoliHouse这个名字。至于它和动画名之间夹杂了多少杂乱的字符并不在乎。Medalist\s\-\s: 正则寻找单词Medalist。字符之后紧跟着 一个空格(\s)。 连字符-衔接。 末尾又是一个空格(\s)。(?=1[3-9]|2[0-1]): 它确认后面紧贴着的数字必须处于特定的区间。这个区间是 13到19,或者是20到21。
替换的文本部分
通过正则,我们找到了内容,内容是Medalist - 。然后输入Medalist.S02E 把标题换成了[喵萌奶茶屋&LoliHouse] 金牌得主 / Medalist.S02E14 [WebRip 1080p HEVC-10bit AAC][简繁日内封字幕] ,现在进入下一步。
被计算区域
替换后的标题里面会有多个数字,比如02,14,1080,10,系统就不知道以哪个为准来计算,所以就使用S02E <> WebRip 来锁定14,告诉系统我这边的数字在S02E后面,在WebRip前面,那可不就是14了么
计算方法
14 - 13 = 1。最后的标题那就是[喵萌奶茶屋&LoliHouse] 金牌得主 / Medalist.S02E1 [WebRip 1080p HEVC-10bit AAC][简繁日内封字幕] 。
种子的文件名称也同理,能套用这套识别词,所以订阅识别词和全局识别词都写一样就成。如果种子文件的名称用不了这个识别词,那就在全局识别词里面再加一个识别词。
测试
对于正则的测试,可以使用这个网站来先试一下正则表达式:
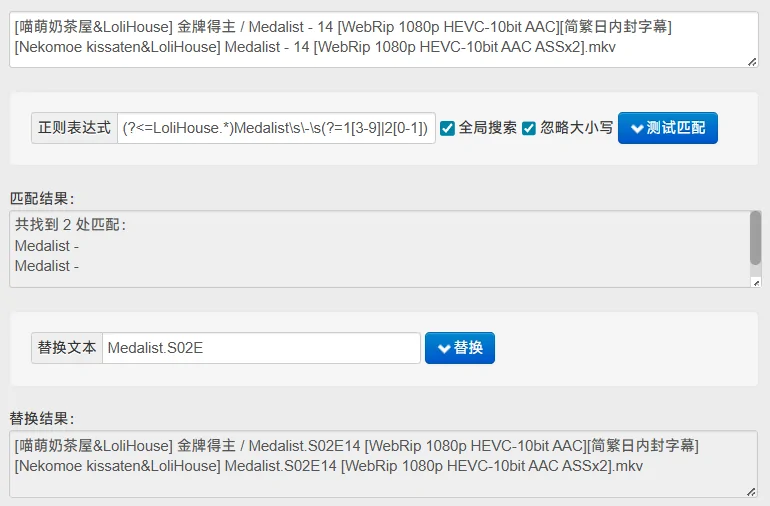
在系统左上角的识别中,可以测试我们的全局识别词。
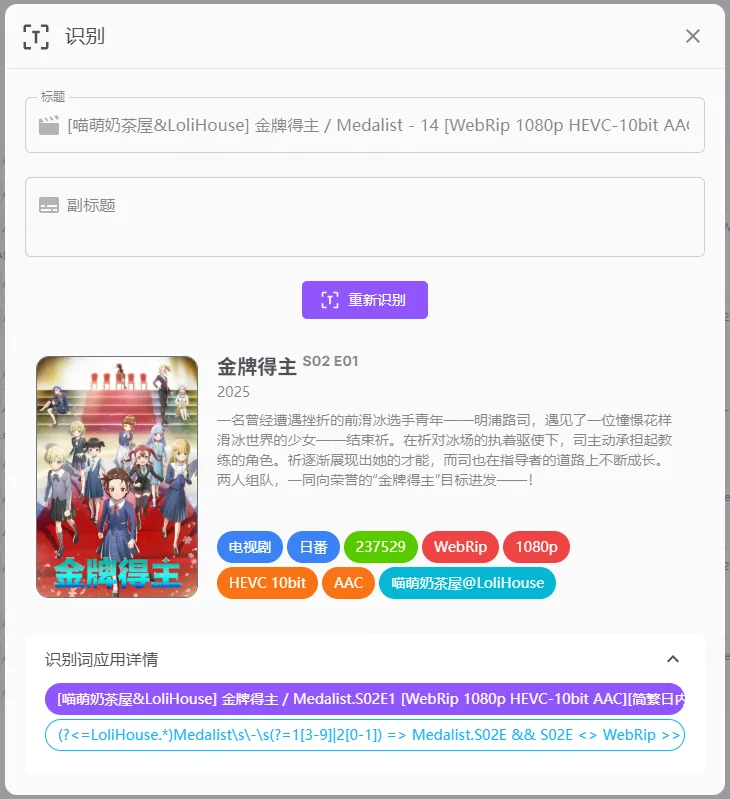
结果
订阅搜索和推送下载都能正常识别和刮削


注意事项
[绿茶字幕组] 金牌得主 第二季 / Medalist S2 [14][WebRip][1080p][简日内嵌] 的识别词写法 (?<=绿茶字幕组.*)Medalist\sS2\s\[(?=1[3-9]|2[0-1]) => Medalist.S02E && S02E <> ]\[WebRip >> EP-13 。
写这个的原因是我想说前定位词与后定位词也是需要正则的,比如后面 S02E <> ][WebRip 就是没办法出来的,它只能使用S02E <> ]\[WebRip 或者S02E <> ] 才能对应成功。
插件
麻烦,复杂,不想看,有没有办法? 有!
一个是简单的搜索订阅,看到自己喜欢的剧,有可靠的源,就直接订阅完事了,然后订阅里面如果有识别词,复制一份到全局识别词里面去。
另一个是安装插件共享识别词 ,然后在默认的识别词里面我加一个神秘小网站,把这个地址追加到里面,能识别我最喜欢的一个站的识别词。
总结
一般情况下,热播的剧搜索订阅就能找到,而我看片的胃口正好和NEST重合度比较高,直接订阅就行,拿到了订阅识别词直接复制一份到全局识别词内,不用动脑子,非常的棒!

我嘞个骚岗,辉夜姬真元气